
Learning REGEX (and use with Powershell)
Short introduction
So at our head branch, we have what’s called a service monitor. It is a website where the status of certain national applications is being displayed. Years ago a colleague created a sort off slideshow-ish website that displays certain data.
- New tickets today
- Tickets solved
- The weather forecast (scraped)
- …
- The national service monitor.
The idea was to always know what was going on. In the past we used to scrape the service monitor with PHP. But after years of not having used PHP, i found it time to try and do this with Powershell and REGEX. The idea is, when it changes, a sound needs to be played.
This would notify all the IT-staff that somethings up.
REGEX has always been on my radar but i never really took a good look at it. So i decided to search for some documentation and found a great resource : https://github.com/zeeshanu/learn-REGEX
The idea was to do a sort off self-thought crash course about REGEX to get the basics down. After i read the documentation, i started off with some simple examples. A great tool to practice was: https://REGEX101.com
Putting what i’ve learned to good use
So to practice, i set out to scrape some news websites, more particular soccernews. Since i’m a fan of RSC Anderlecht (a Belgian soccer-team) i decided on scraping the daily news from two websites i visit the most.
So here is the code and some of my findings:
We start by surfing to the main website and grab all URL’s that link to the news articles and their timestamps.
$VOETBAL24 = "
#######################
#VOETBAL24.BE
#######################"
write-host $VOETBAL24 -BackgroundColor Yellow
Add-Type -AssemblyName System.Web
$url = 'http://www.voetbal24.be'
$index = iwr $url -UseBasicParsing
$mainpart = $null
$payload = $null
$arrOfLinks = [REGEX]::Matches($index, '(?ms)<td><!.*?(\d{2}:\d{2})<.td>.*?(<a href=")(\/news\/.*?)\">')
How to read the REGEX
So this first REGEX is saying:
$arrOfLinks = [REGEX]::Matches($index, '(?ms)<td><!.*?(\d{2}:\d{2})<.td>.*?(<a href=")(\/news\/.*?)\">')
- Look for a TD,
- followed by, <!,
- followed by whatever,
- followed by 2 digits,
- followed by :,
- followed by again 2 digits,
- followed by <\td>,
- followed by whatever (this part is to get the time of the post),
At this point we have the timestamps. Now we also need the URL so that we can browse to the articles. We continue our REGEX with:
- look for <a href=>
- followed by /news/
- followed by whatever,
- followed by a closing of the a tag.
So the idea of approaching a selection like this, is really new. First look for item A, followed by B, followed by C. Knowing this, helped me a lot in the more difficult parts.
Groups
Everyting we place in between () is called a group. They are numbered starting from 0 (being the full result of the REGEX (so a concatination off all groups in a way)). Usually you’ll start using group[1] up to whatever groups you have. So you’ll use these groups to select what you want to use from your REGEX.
To explain, say you have a HTML tag with:
<h1< a href="/news/anderlecht-fans-willen-deze-coach-als-opvolger-van-weiler">Anderlecht-fans willen deze coach als opvolger van Weiler</a></h1>
And you would like to select just the part in between the “” so that you can form a new url. Your REGEX would look something like this (other variations are possible). The news is included because i only wanted these type of URL’s.
<a href="(.news.*?)"')
So this way group[1] would containt ALL that is in between the “” or more exactly :
/news/anderlecht-fans-willen-deze-coach-als-opvolger-van-weiler
Captures
If we look at the output of
$uri = $site.groups
then we see that the above REGEX has certain groups.
Seeing that the groups contained too much data at onces, we are using the captures to get what we want. This took some time to figure out! So i hope by me posting this, it might help someone else in the future. A more detailed explanation can be found over at Reddit, a special thanks to the user Ka-splam.
By using the captures, i can “trim down” the group and select what i want. In this case the hour and the URL starting from “/news”.
- Group 1 being: (\d{2}:\d{2}) (or the time 12:45)
- Group 2 and 3 make up a url
Groups : {<td><!-- 2017-09-11 16:15:00 --> 16:15</td>
<td><a href="/news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern">, 16:15, <a href=", /news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern}
Success : True
Captures : {<td><!-- 2017-09-11 16:15:00 --> 16:15</td>
<td><a href="/news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern">}
Index : 21728
Length : 121
Value : <td><!-- 2017-09-11 16:15:00 --> 16:15</td>
<td><a href="/news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern">
Success : True
Captures : {16:15}
Index : 21761
Length : 5
Value : 16:15 # **we need this**
Success : True
Captures : {<a href="}
Index : 21788
Length : 9
Value : <a href="
Success : True
Captures : {/news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern}
Index : 21797
Length : 50
Value : /news/zo-veel-anderlecht-fans-gaan-mee-naar-bayern # **we need this**
With the above output, i’m able to construct my needed url.
foreach ($site in $arrOfLinks[0 .. 5])
{
$hr = $site.groups.captures[1].value # too much data in group, so we use captures
$uri = $site.groups.captures[3].Value
$link = "http://www.voetbal24.be" + $uri # We construct our URL so that we can scrape the article
# Retrieve all data
$payload = (iwr $link -UseBasicParsing | select content -ExpandProperty content)
A REGEX based upon the result of a previous REGEX
So here is a second part that took some time to figure out. I didn’t want to make my script go through all the sourcecode more times than was needed.
I start by taking a chunk of code out of the full sourcecode of the webpage. This chunk of code, which i named “$mainpart” contains all the data that i need. From here on out, i’ll use my $mainpart to perform further filtering on.
# Get main data part to filter further
$mainpart = [REGEX]::matches($payload, '(?ms)(<!-- Content)(.*)( <!-- Twitter -->)') |
% { $_.groups[0].value }
Now with the first REGEX, we have all the data we need. So now having stored that in $mainpart, we can approach it by another REGEX, storing that output in a different variable.
# PART I based on mainpart
$intro = [REGEX]::Matches($mainpart, '(?ms)<p class="intro">.*?<.p>').groups[0].value
Since the text and intro are having different HTML markup, we are using yet another REGEX (based off of our first one) to retrieve the article text itself.
# PART II based on mainpart
$articleText = [REGEX]::matches($mainpart, '(?ms)(<p class="description">.*?)(<!-- Twitter -->)') |
% { $_.groups[0].value }
Again we are a new REGEX to get the tiltle, the possibilities here are endless really.
# PART III based on mainpart
$title = [REGEX]::matches($mainpart, '(<h1>.*?<.h1>)') |
% { $_.groups[0].value + "`n" }
#$matches | Format-Table name, value -Wrap -AutoSize
#Display data in readable format
$title = [System.Web.HttpUtility]::HtmlDecode($title) -replace "<.*?>", ''
if ($articleText -like '*anderlecht*' -or $intro -like '*anderlecht*') {
write-host $title$hr -ForegroundColor green
}
else {
write-host $title$hr -ForegroundColor cyan
}
""
[System.Web.HttpUtility]::HtmlDecode($intro) -replace "<.*?>", ''
""
[System.Web.HttpUtility]::HtmlDecode($articleText) -replace "<.*?>", ''
"-" * 50
""
<#
Replace all html code form parsed website, this is a trick i found at : http://www.powershellmagazine.com/2014/07/09/pstip-decoding-an-html-encoded-string/
#>
}
So this Regex after Regex was only possible with the .net class [REGEX]::Matches With the Powershell built-in regex function -match() i wasn’t able to do this.
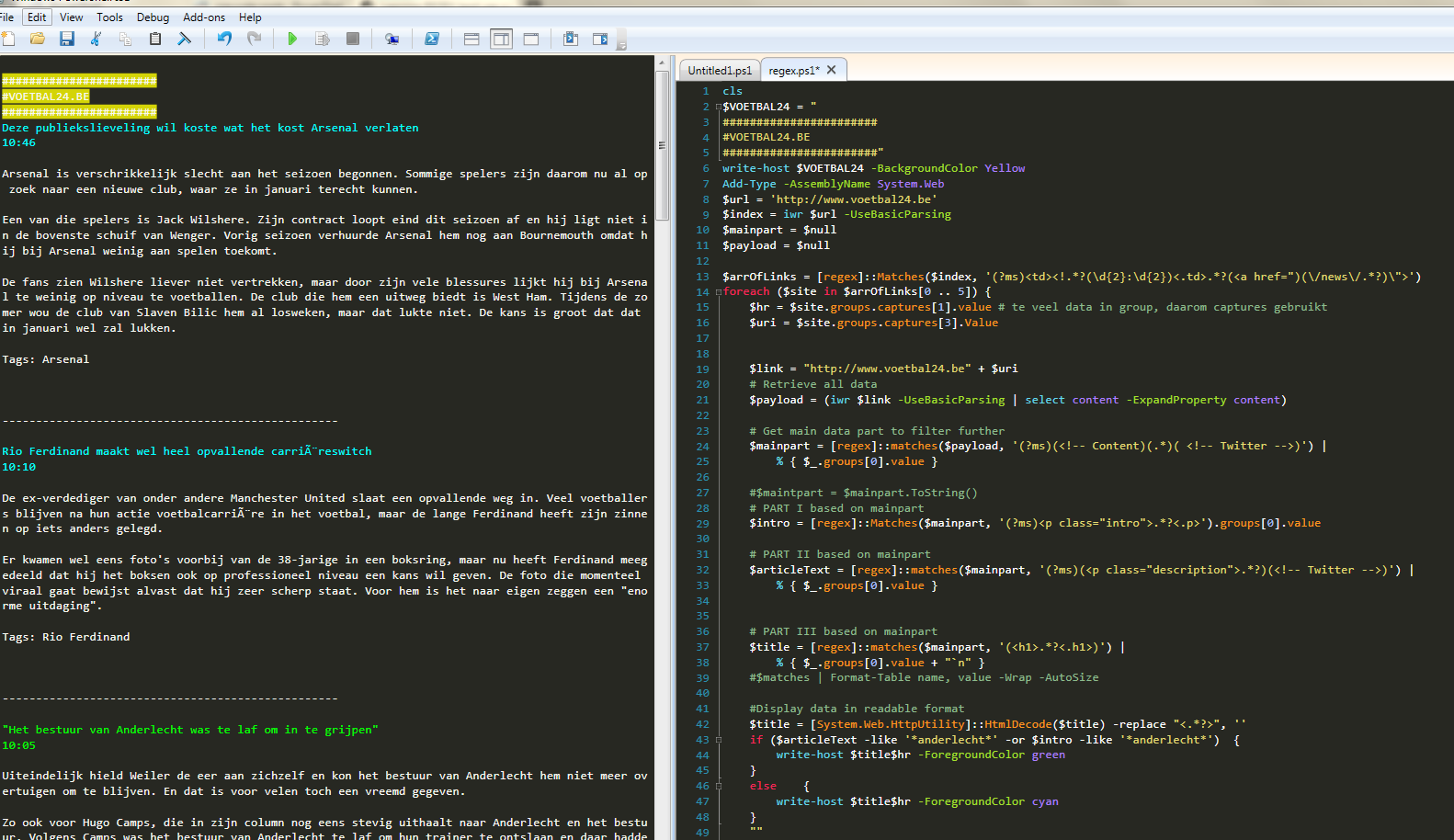
The output of the script looks like this:
Leave a Comment